La visualización de datos forma parte del proceso de análisis de datos y es una herramienta necesaria para identificar las tendencias y los patrones en conjuntos de datos grandes. Un simple gráfico puede demostrar la conexión entre los parametros que nos interesan y entender la idea detrás de los miles de números o palabras de un archivo. En la epoca del Big Data la visualización de datos es crucial para el análisis de las cantidades masivas de información y la toma de decisiones basadas en ellos.
Así, la visualización de datos la utilizaremos en dos casos:
- Antes de empezar nuestro análisis. Cuando queremos hacer la predicción y entrenar un modelo de aprendizaje automático, es importante saber qué parametros podemos utilizar para mejorarlo. La visualización de datos nos ayuda a entender qué tipos de datos tenemos, las relaciones entre ellos y los parametros claves.
- Para demostrar el resultado. Tenemos que reflejar los frutos de nuestra investigación o del modelo de aprendizaje automático de una manera fácil de entender, visible para el cliente y el consumidor, y no hay nada mejor que una implementación visual que represente lo que hemos conseguido.
¿Qué herramientas de Python podemos utilizar para la visualización de datos?
Python ofrece una gama amplia de herramientas que permiten construir gráficos y tablas. En este artículo vamos a ver los ejemplos de la visuzalización de datos usando las bibliotecas Pandas, Matplotlib y Seaborn, todas libres y de código abierto. Pandas, una herramienta potente de análisis y manipulación de datos, nos facilita el trabajo con tablas numéricas y series temporales. Usaremos solo algunas funciones de esta biblioteca necesarias para nuestro objetivo. Matplotlib es la base de otras bibliotecas de Python creadas para la visualización de datos, que permite generar gráficos a partir de datos contenidos en listas o arrays. Seaborn, basada en Matplotlib, proporciona una interfaz más sencilla y gráficos de mejor aspecto estético y permite visualizar la información de una manera muy fácil.
Para demostrar los métodos más comunes de visualización de datos usaremos Jupyter Notebook como nuestro editor de código, ya que permite ver el resultado al mismo tiempo con la ejecución del código e introducir los cambios de una manera muy fácil. La información para el análisis la extraeremos desde Kaggle, una plataforma de competiciones en el ámbito de inteligencia artificial, que contiene datasets de distintos tipos y formatos de datos y permite obtener el material para las tareas de aprendizaje automático y también para la creación de tutoriales como el nuestro.
El objetivo de este artículo es introducir algunas herramientas de la visualización de datos en Python y usando datasets reales enseñar sus habilidades. Veremos, como instalar las bibliotecas necesarias y crearemos gráficos usando Matplotlib y Seaborn. Seguiremos paso a paso con cada herramienta y cada gráfico para luego poder aplicar las funciones descritas a cualquier dataset que queramos.
La lista de los gráficos que veremos con Matplotlib:
Y con Seaborn:
Instalación de las herramientas necesarias
Para usar las herramientas de visualización de datos mencionadas, primero tenemos que instalarlas. Dependiendo de que distribución usamos, el proceso de instalación y los comandos que tenemos que ejecutar serán un poco distintos. Vamos a ver como se instala cada una de las bibliotecas y luego pasamos al proceso de la visualización.
Instalamos Pandas
Pandas está disponible para todas las versiones de Python 3. Si usamos Anaconda, instalamos esta biblioteca ejecutando el siguiente comando:
conda install pandas
Para los usuarios de pip tenemos que ejecutar el siguiente comando:
pip install pandas
Instalamos Matplotlib
Si usamos Anaconda, para instalar Matplotlib tenemos que ejecutar el siquiente comando:
conda install -c conda-forge matplotlib
Para instalar esta biblioteca en macOS, Windows y Linux/Unix usando pip ejecutamos:
pip install matplotlib
Si usamos la versión de Python que viene con nuestra distribución de Linux, tenemos que usar el administrador de paquetes ejecutando el siguiente comando:
sudo apt-get install python3-matplotlib
Instalamos Seaborn
Para los usuarios de Anaconda esta biblioteca se instala mediante el comando:
conda install seaborn
Para los usuarios de pip en macOS, Windows y Linux/Unix Seaborn se instala ejecutando el siguiente comando:
pip install seaborn
Además de todas las bibliotecas necesarias, ya instaladas, usaremos algunos módulos de Python adicionales, necesarios para ciertos tipos de gráficos en particular. El proceso de instalación e importación de estos módulos lo veremos a continuación.
Tenemos que acordarnos de que siempre que en Python obtenemos un error tipo:
No module named 'nombre del módulo'
significa, que tenemos que instalar el módulo que nos falta.
Instalamos Jupyter Notebook
Uno de los IDEs que mejor sirve para la visualización de datos es Jupyter Notebook. En este artículo todos los procesos los vamos a ejecutar a través de este IDE. Si todavía no hemos usado esta herramienta, la tendremos que instalar. En el caso de usar Anaconda ejecutamos:
conda install jupyter notebook
Para instalarlo usando pip en macOS, Windows, Linux/Unix el comando de instalación sería:
pip install jupyter notebook
La visualización de datos con Matplotlib
Ya podemos empezar a visualizar nuestros datos. Veremos algunos de los métodos más populares que se usan en Python, utilizando datasets disponibles en Kaggle. Para facilitar el proceso, al descargar los datasets guardaremos los ficheros en la misma carpeta donde vamos a tener nuestro notebook. Seguiremos paso a paso y veremos los resultados que se pueden obtener con las funciones de Matplotlib.
Abrimos el nuevo notebook e importamos las bibliotecas que vamos a utilizar:
import pandas as pd
import matplotlib.pyplot as plt
Ahora importamos el fichero que contiene la información que queremos visualizar – en nuestro caso es un dataset que contiene los datos sobre los índices de calidad de vida, seguridad, salud, etc. por paises para el año 2020. Usaremos la función de Pandas pd.read_csv() que nos permite leer un fichero de formato .csv, convertiéndolo en un DataFrame. Guardamos el dataset en la variable df_countries:
df_countries = pd.read_csv("Quality of life index by countries 2020.csv")
Vamos a ver, como están distribuidos los datos en nuestro fichero usando las funciones de Pandas. Podemos ver las primeras 5 líneas del dataset usando la función df.head():
df_countries.head()
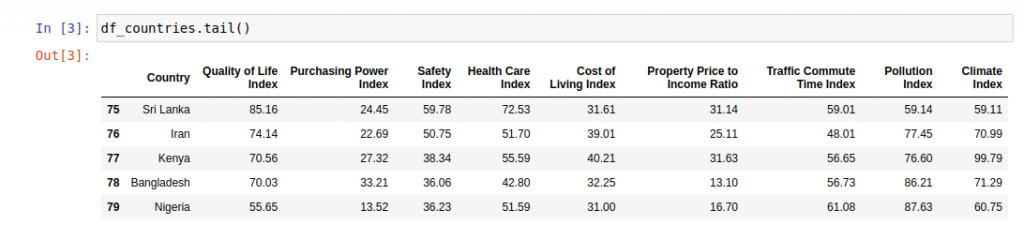
O las últimas 5 líneas con df_tail():
df_countries.tail()
También podemos obtener la información sobre el tipo de datos del DataFrame y la lista de todas las columnas usando df.info(). Es necesario saber que tipo de datos contiene la columna para poder hacer las operaciones de una manera correcta evitando los errores. Para averiguar esta información ejecutamos:
df_countries.info()
Obtenemos la siguiente tabla:
Para ver la información estadística sobre el contenido del dataset Pandas tiene una función df.describe():
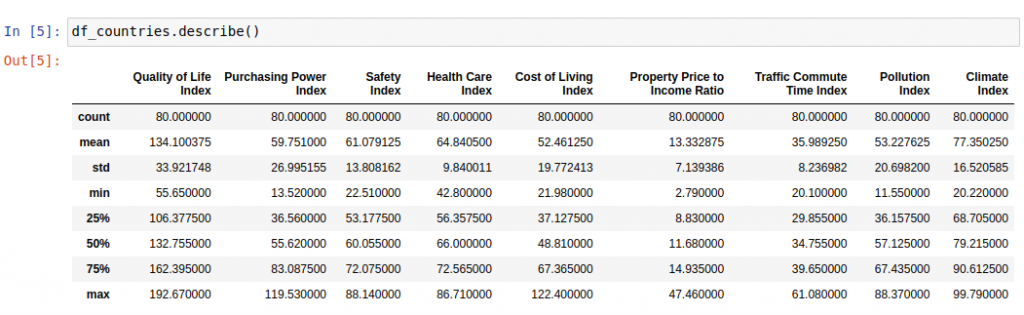
Así, estas funciones de Pandas podemos utilizarlas para ver lo que está dentro de nuestro dataset y en base a la información obtenida decidir que gráficos podemos crear para visualizar lo que nos interese.
Gráfico lineal (plot)
Vamos a empezar a construir los gráficos. Veremos, si hay una correlación entre el Índice de Calidad de Vida y el Índice de Salud. Para ello creamos un gráfico lineal usando Matplotlib. Este tipo de gráficos se usa para representar series en función del tiempo y comprobar el cambio de tendencia de los datos, pero también podemos usarlo para ver si hay correlación entre dos variables.
A la hora de construir el gráfico en Matplotlib es importante tener en cuenta que cuando asignamos los nombres de las columnas de nuestro dataset a los ejes, el nombre tiene que coincidir con el que aparece en la columna, de otro modo no se reconocerá la información.
Para asignar a los ejes los valores de las columnas del dataset, tenemos que poner el nombre de la variable que contiene el dataset (‘df_countries’ en nuestro caso) y el nombre de la columna entre corchetes [‘nombre de la columna’].
Asignamos al eje X los valores de la columna ‘Quality of Life Index’ (Índice de Calidad de Vida) y al eje Y los valores de ‘Health Index’ (Índice de Salud)
x = df_countries['Quality of Life Index']
y = df_countries['Health Care Index']
Nombramos los ejes usando las funciones plt.xlabel() y plt.ylabel():
plt.xlabel('Calidad de Vida')
plt.ylabel('Salud')
También ponemos el título a nuestro gráfico usando plt.title():
plt.title('Relación entre Calidad de Vida y Salud')
Construimos el gráfico plt.plot() y lo mostramos plt.show():
plt.plot(x,y)
plt.show()
Así será el resultado:
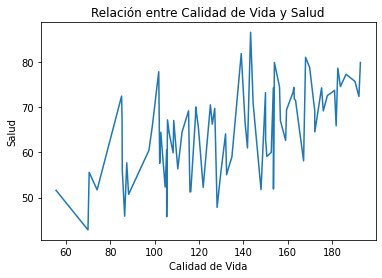
Como podemos ver, existen extremos en el gráfico pero la tendencia es ascendente y en general el aumento del índice de salud mejora la calidad de vida.
Vamos a ver ahora, como depende la calidad de vida de la contaminación. Aparte, vamos a cambiar el color de nuestro gráfico, ya que el gráfico anterior tenía un color elegido por defecto por Matplotlib. Podemos usar tanto los colores por sus nombres en inglés como ‘red’ (rojo), ‘green’ (verde), etc., como usar el código de color específico. Por ejemplo, vamos a elegir un color con el código #50D1A7. Aparte, podemos elegir la transparencia de nuestro gráfico usando el parámetro alpha.
Primero, asignamos al eje X los valores de la columna ‘Quality of Life Index’ (Índice de Calidad de Vida) y al eje Y los valores de ‘Pollution Index’ (Índice de Contaminación):
x = df['Quality of Life Index']
y = df['Pollution Index']
Nombramos los ejes y el gráfico:
plt.xlabel("Calidad de vida")
plt.ylabel("Contaminación")
plt.title('Relación entre Calidad de Vida y Contaminación')
Construimos el gráfico, incluyendo los ajustes de color y de transparencia y usamos la función plt.show() para mostrarlo correctamente:
plt.plot(x,y, color = '#50D1A7', alpha=0.7)
plt.show()
Obtenemos la siguiente línea azul. Este gráfico nos demuestra una correlación clara entre el nivel de contaminación y la calidad de vida – menos contaminado, mejor:
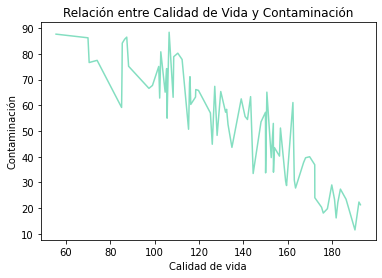
De esta manera, hemos visto como construir los gráficos lineales usando la biblioteca Matplotlib, de que nos sirven, y como ajustar algunos parámetros de este tipo de gráficos para nuestras necesidades.
Diagrama de tallo y hojas (stem plot)
Este tipo de gráfico ayuda a visualizar la forma de distribución. Vamos a ver como se refleja la correlación entre la calidad de vida y la contaminación si usamos el diagrama de tallo y hojas. Asignamos los ejes, el título y los nombres de los ejes de la misma manera que en el paso anterior:
df_countries = pd.read_csv("Quality of life index by countries 2020.csv")
x = df_countries['Quality of Life Index']
y = df_countries['Pollution Index']
plt.xlabel("Calidad de vida")
plt.ylabel("Contaminación")
plt.title('Relación entre Calidad de Vida y Contaminación')
Creamos el gráfico usando la función plt.stem(). Vamos a cambiar el tipo de líneas verticales a puntos (:):
plt.stem(x,y, ':')
plt.show()
Obtenemos el siguiente gráfico:
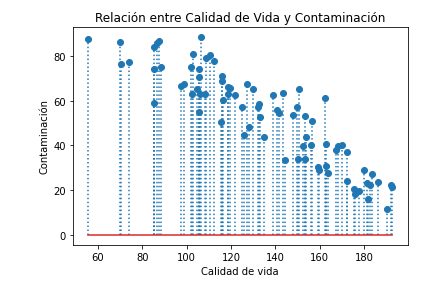
Con este tipo de gráfico podemos ver los valores de una forma mas detallada, ya que con el gráfico lineal solo veíamos la tendencia general sin valores destacados.
Gráfico de dispersión (scatter plot)
Los gráficos de dispersión sirven para representar la relación entre dos variables numéricas. Los círculos en este tipo de gráfico informan del valor de cada punto y también de los patrones de datos en conjunto. Vamos a seguir usando la correlación entre la contaminación y la calidad de vida para ver un ejemplo de gráfico de dispersión.
Ya sabemos como asignar los valores a los ejes, nombrar los ejes y elegir el título del gráfico. Aparte de esto, en el gráfico de dispersión también podemos definir el tamaño de los círculos (s=80 en nuestro ejemplo). Para tener la visualización aún más clara, añadiremos una leyenda usando plt.legend():
df_countries = pd.read_csv("Quality of life index by countries 2020.csv")
x = df_countries['Quality of Life Index']
y = df_countries['Pollution Index']
plt.xlabel("Contaminación")
plt.ylabel("Calidad de vida")
plt.title('Como depende la calidad de vida del nivel de contaminación')
plt.legend(["Contaminación"])
plt.scatter(x,y,s=80, alpha=0.5, color="green")
plt.show()
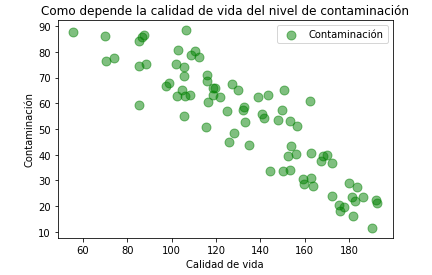
Como podemos ver, los valores están correlacionados y la tendencia es descendente. En este gráfico en comparación con el gráfico lineal vemos más claramente la dispersión de los valores junto a la tendencia general.
Podemos guardar el gráfico de dispersión que hemos obtenido usando la función savefig(). Para aplicarla, tenemos que asignar la función de la construcción del gráfico a una variable (fig1) y determinar como se llamará el fichero que contiene la imagen que queremos guardar:
fig1=plt.scatter(x,y,s, alpha=0.5, color="green")
fig1.figure.savefig('myfigure.png')
Gráfico circular o de pastel (pie chart)
El gráfico de pastel (pie chart) es muy útil para representar datos cualitativos o categóricos, mostrando la proporción que le corresponde a cada categoría. Lo podemos usar para representar los tipos de gastos, la cantidad de turistas por ciudad (por ejemplo dentro de Europa) y muchas cosas más. En nuestro caso vamos a crear este gráfico usando un pequeño dataset de finanzas personales, mostrando el porcentaje de cada tipo de gasto asignado al presupuesto.
Seguimos los pasos ya descritos anteriormente – primero, aplicamos la función pd.read_csv() de Pandas para descargar nuestro fichero en el formato .csv y convertirlo en DataFrame (df_budget):
df_budget = pd.read_csv("Budget.csv")
Vamos a ejecutar la función df.info() para obtener la información sobre nuestro dataset:
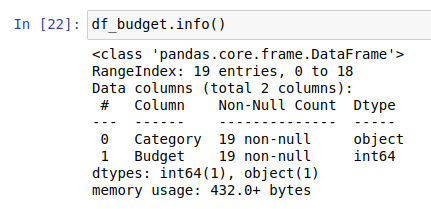
Para poder crear un gráfico de pastel, necesitamos sumar los gastos por cada categoria. Esto se consigue mediante la función de Pandas groupby() y la función sum(). Sin aplicar estas dos funciones no podremos construir un pie chart apropiado. Entre corchetes [] tenemos que poner el valor numérico [‘Budget’] y entre paréntesis () mencionar la columna con los nombres de tipo de gastos (‘Category’):
gasto_type = df_budget.groupby('Category')['Budget'].sum()
Creando un gráfico de pastel con la función plot.pie() podemos decidir si indicar también los porcentajes de cada trozo (autopct=»%1.1f%%» ) y el radio del círculo (radius=2):
gasto_type.plot.pie(autopct="%1.1f%%", radius = 2)
plt.show()
Este es el gráfico que obtenemos:
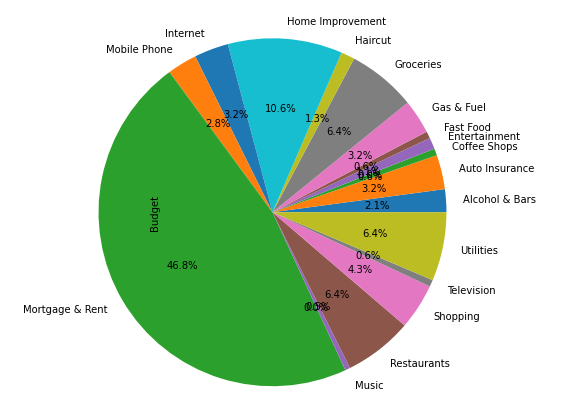
Como podemos ver claramente, la mayor parte del presupuesto, casi el 47% se gasta en Mortgage & Rent (Hipoteca & Alquiler). Pero los valores más pequeños se mezclan y no se ve nada claro. Vamos a agrupar los valores de los gastos de menos de 50 dolares en un trozo de pie chart llamado ‘other‘. Eso se consigue de la siguiente manera: asignamos el límite de 50 a una variable ‘limit’; la variable ‘gastos‘ va a contener la suma del presupuesto por cada categoría; ‘gastos_max’, una nueva variable, va a guardar todos los valores que están por encima de 50 dolares; y con la cuarta línea del código (gastos_max[‘other’]) asignamos los valores que son de menos de 50 dolares a la categoría ‘other’ y los sumamos:
limit = 50
gastos = df_budget.groupby('Category')['Budget'].sum()
gastos_max = gastos[gastos > limit]
gastos_max['Other'] = gastos[gastos <= limit].sum()
Creamos el gráfico de pastel nuevo, usando ‘gastos_max’ como base. Aplicamos la función plt.ylabel(‘ ‘) para que el gráfico sea más bonito y la leyenda del eje Y no aparece por la mitad:
gastos_max.plot.pie(autopct="%1.1f%%",radius=2)
plt.ylabel('')
plt.show()
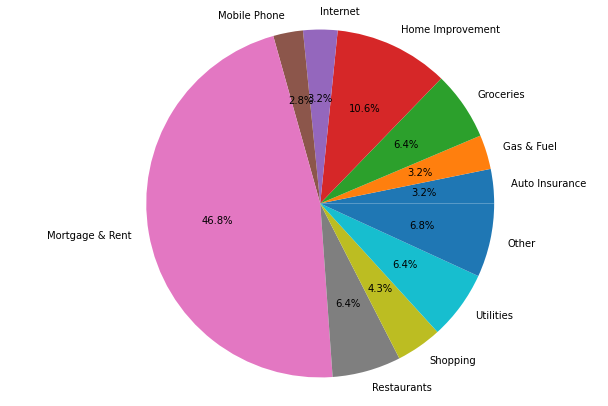
Así, los gastos del presupuesto que son menores de 50 dolares se han agrupado en una sola porción y ahora el gráfico es más entendible y más bonito.
Gráfico de barras (bar plot)
Vamos a ver, como se puede reflejar la información sobre el presupuesto de una persona usando el gráfico de barras. Para esto creamos un eje ‘categoría’, que va a contener las categorías del presupuesto del dataset (categoria=df_budget[‘Category’]) y un eje ‘budget’ (budget=df_budget[‘Budget’]) que contiene los gastos según cada categoría:
df_budget = pd.read_csv("Budget.csv")
categoria = df_budget['Category']
budget = df_budget['Budget']
Configuramos el tamaño del gráfico, asignamos el título y usando la función ax.barh() creamos nuestro gráfico de barras:
fig, ax = plt.subplots(figsize =(16, 9))
ax.set_title('La distribución de los gastos',
loc ='left', )
ax.barh(categoria, budget)
plt.show()
Obtenemos el siguiente resultado:
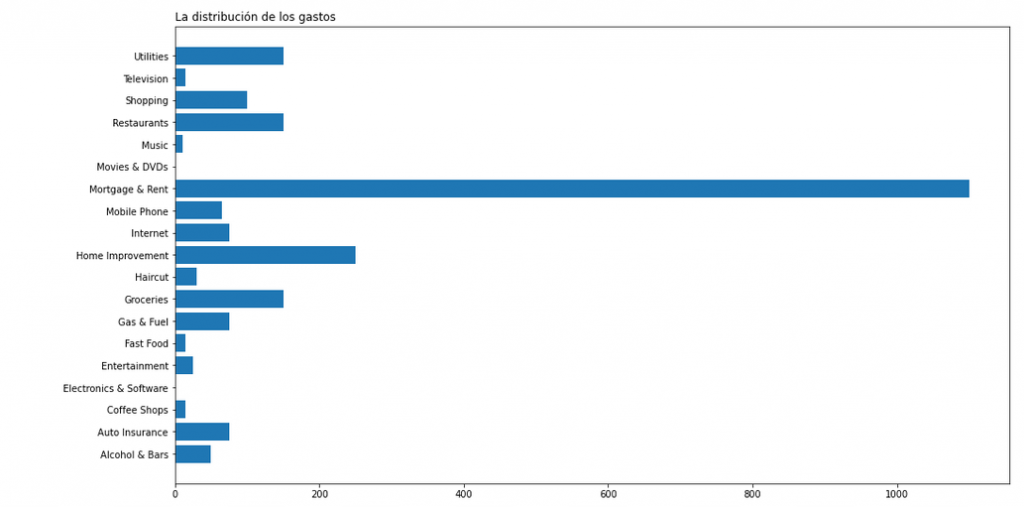
Como podemos ver, el gráfico de barras nos ayuda a representar la comparación entre los valores de la misma categoría y muestra las diferencias de una manera muy clara.
FreqDist plot
Esta herramienta es útil si nos dedicamos a las tareas de PLN. FreqDist es la parte de la biblioteca NLTK y ayuda a representar las palabras más frequentes en el texto. Si todavía no tenemos instalado NLTK, lo hacemos usando la pequeña guia de este artículo. Para usar el módulo FreqDist primero tenemos que importar la biblioteca NLTK, y luego importar el módulo (from nltk.probability import FreqDist). Aparte de esto tenemos que importar la biblioteca string, y los módulos stopwords y word_tokenize de NLTK. Esta es la lista completa de las herramientas que necesitaremos importar:
import nltk
import string
from nltk.probability import FreqDist
nltk.download('stopwords')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
Para visualizar las palabras más frequentes primero necesitamos un texto en formato .txt, guardado en la misma dirección que nuestro jupyter notebook. Podemos usar cualquier texto, para nuestro ejemplo usaremos una parte de este artículo.
Abrimos el fichero que contiene el texto, lo leemos y muy importante, lo convertimos en una string. Si no lo hacemos, a la hora de tokenizar el texto, obtendremos el siguiente error:
TypeError: expected string or bytes-like object
Así sería la importación correcta de nuestro fichero ‘articulo.txt’ :
with open('articulo.txt', 'r', encoding='utf-8') as f:
nuestro_texto = str(f.readlines())
Ahora vamos a crear e importar una función que ayuda a tokenizar el texto por palabras. Se ejecuta con el módulo word_tokenize() de la biblioteca NLTK importado previamente.
def tokenize_words(text):
text_tokenized = word_tokenize(text)
return text_tokenized
text_token = tokenize_words(nuestro_texto)
Queremos extraer las palabras más frequentes del texto, y para ello nos interesa que no sean palabras vacías, puntuación o dígitos. Por eso, vamos a crear una variable ‘eliminar’, que contenga toda la información que no queremos tener en nuestro gráfico final, uniéndola en un set:
eliminar = set(stopwords.words('spanish') + list(string.punctuation) + list(string.digits))
Creamos una nueva lista (‘filtered_text’) que contiene todas las palabras salvo las que están en la lista ‘eliminar’:
filtered_text = [word for word in text_token if word not in eliminar]
Ahora podemos crear el gráfico que muestra las 10 palabras más frequentes de nuestro artículo aplicando la función FreqDist a nuestro texto filtrado y usando la función plot() para crear el gráfico. Como podemos ver, el número de las palabras que queremos representar se define a la hora de ejecutar la función y en lugar de 10 palabras podemos elegir cualquier otro número:
fdist_filtered = FreqDist(filtered_text)
fdist_filtered.plot(10, title='Distribución de frecuencia para los 10 tokens más comunes en nuestra colección de texto (excluyendo palabras vacías y puntuación)')
Así será nuestro resultado:
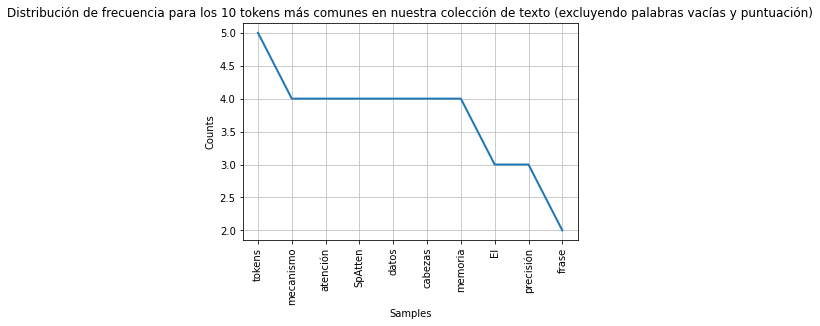
Con este gráfico podemos ver que la palabra más frequente de nuestro texto es ‘tokens’ y se encuentra 5 veces, otras palabras que también se utilizan mucho son ‘mecanismo’, ‘atención’, ‘SpAtten’, ‘datos’, ‘cabezas’ y ‘memoria’. Esto nos ayuda a comprender que tipo de información contiene el artículo y cuales son las palabras clave.
Así son los gráficos más populares de la biblioteca Matplotlib. Ahora vamos a ver que opciones nos ofrece Seaborn, otra herramienta potente para la visualización de datos.
La visualización de datos con Seaborn
Seaborn es una biblioteca basada en Matplotlib, que se usa sobre todo para la creación de gráficos estadísticos, y está integrada estrechamente con las estructuras de datos de Pandas en Python. Permite visualizar los datos de una manera fácil y tiene una variedad de gráficos distintos para muchos tipos de análisis. Las características que más destacan a esta biblioteca son:
- Manejo de los datos: Seaborn es capaz de representar fácilmente distribuciones de datos o agregaciones sin utilizar muchas líneas de código
- Visualizaciones disponibles: La galería de Seaborn es una de las más amplias, desarrollada para representar el análisis estadístico de una forma sencilla
- Personalización: El aspecto visual de un gráfico que es bastante laborioso con Matplotlib, se desarrolla de una forma muy sencilla con Seaborn.
Vamos a ver cómo son los gráficos que podemos crear con esta biblioteca y como los podemos usar para el análisis de nuestros datos.
Primero importamos las bibliotecas que vamos a necesitar, Pandas y Seaborn:
import pandas as pd
import seaborn as sns
Vamos a usar un dataset que contiene las respuestas de una encuesta sobre la calidad de vida, basada en parametros como las horas de sueño, el consumo de frutas y verduras, las meditaciones semanales, etc. Además, tiene una columna con los valores calculados del balance de vida (work-life balance). Este dataset nos sirve muy bien para poder ver las relaciones entre las variables.
Guardamos el dataset en la misma dirección donde tenemos el notebook. Usamos la función pd.read_csv() de Pandas para descargar nuestro fichero en el formato .csv y convertirlo en DataFrame (df_wellbeing):
df_wellbeing = pd.read_csv("wellbeing_dataset.csv")
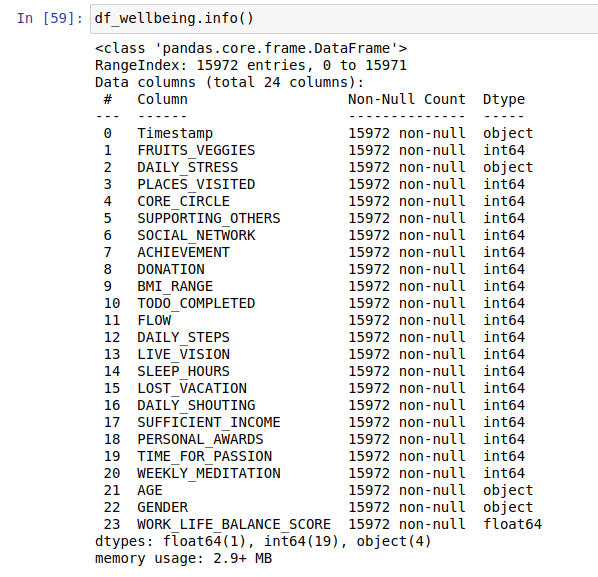
Vamos a ejecutar la función df.info() para obtener la información sobre nuestro dataset:
df_wellbeing.info()
Ahora vamos a ver la distribución de datos en el dataset usando df.head():
df_wellbeing.head()
Gráfico lineal (plot)
Crearemos un gráfico lineal para ver si hay una correlación entre las horas de sueño («SLEEP HOURS») y el equilibrio entre la vida y el trabajo («WORK_LIFE_BALANCE_SCORE»), usando la función de Seaborn sns.replot(). Asignamos al eje X la columna «SLEEP HOURS» y al eje Y la columna «WORK_LIFE_BALANCE_SCORE». El tipo de gráfico es una línea (kind = «line») y el data es nuestro dataset df_wellbeing:
g = sns.relplot(x="SLEEP_HOURS",
y="WORK_LIFE_BALANCE_SCORE",
kind="line",
data=df_wellbeing)
Obtenemos el siguiente gráfico:
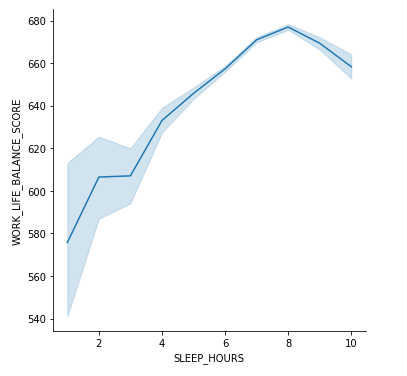
Como podemos ver, la línea azul nos refleja la tendencia general en la que, si dormimos menos de 8 horas, nuestra calidad de vida empeora. Vemos que dormir más de 8 horas tampoco está bien ya que los valores del gráfico descienden después de las 8 horas. La zona de azul más clara nos informa de los valores fuera de la tendencia general – hay gente que durmiendo poco siente que su equilibrio entre la vida y el trabajo está mejor que el de la mayoría.
Es un gráfico general, asi que no podemos ver, si la cantidad de las horas de sueño afecta igual a todas las edades. Seaborn permite añadir al gráfico un parámetro col, donde podemos asignar la columna para dividir nuestros resultados. Así, vamos a mirar como varía el resultado de gráfico anterior según la edad (col=»AGE»):
g = sns.relplot(x="SLEEP_HOURS",
y="WORK_LIFE_BALANCE_SCORE",
col="AGE",
kind="line",
data=df_wellbeing)
Obtenemos 4 gráficos por cada brecha de edad que tenemos en el dataset:
Como podemos ver, a las personas de diferentes edades las horas de sueño les afectan de una manera un poco distinta. Así, el equilibrio entra la vida y el trabajo en caso de los menores de 20 años casi no cambia duerman 8 horas o más.
Gráfico de dispersión (scatter plot)
Vamos a ver otro tipo de gráfico – gráfico de dispersión (scatter plot). Veremos que correlación hay entre las horas de sueño y el equilibrio entra la vida y el trabajo, entre hombres y mujeres por separado (col=»GENDER» ). Aparte, agregamos el dato de meditación semanal, que se reflejará en el gráfico por la intensidad de su color (hue=»WEEKLY_ MEDITATION»):
g = sns.relplot(x="SLEEP_HOURS",
y="WORK_LIFE_BALANCE_SCORE",
col="GENDER",
hue="WEEKLY_MEDITATION",
data=df_wellbeing)
Obtenemos los siguientes resultados:
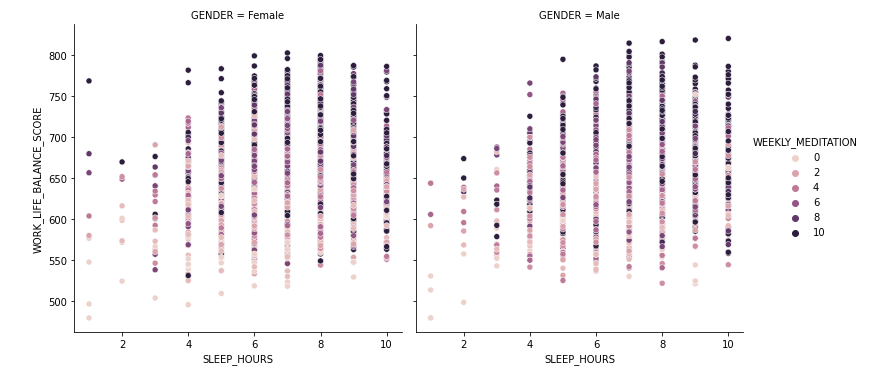
Podemos ver, que las personas que duermen 4 horas o menos, tienen el equilibrio entre la vida y el trabajo más bajo que las personas que duermen más. Aparte, meditar casí siempre es positivo y la gente que medita más días a la semana (tanto los hombres como las mujeres), sube el nivel del equilibrio de vida, aunque duerman pocas horas. Esto se refleja en la intensidad del color que aparece en el gráfico como violeta oscuro (en este tipo de gráficos los colores más oscuros indican valores más altos). Así, el parametro hue nos ayuda a añadir más datos al gráfico y ver las relaciones entre varios parámetros del dataset al mismo tiempo.
Otro ejemplo que podemos ver de este tipo de gráfico usando el dataset anterior sobre los paises, nos va a mostrar más claramente la función del gráfico de dispersión. Asignamos al eje X el índice de la calidad de vida (‘Quality of Life Index’) y al eje Y el índice de la salud (‘Health Care Index’). Como parámetro hue vamos a considerar el índice de contaminación (‘Pollution Index’). Para cambiar el tamaño de los circulitos, asignamos el valor 250, para que sean bastante visibles en el gráfico (s=250):
g = sns.relplot(x="Quality of Life Index",
y="Health Care Index",
hue="Pollution Index",
s=250,
data=df_countries)
Obtenemos la siguiente visualización:
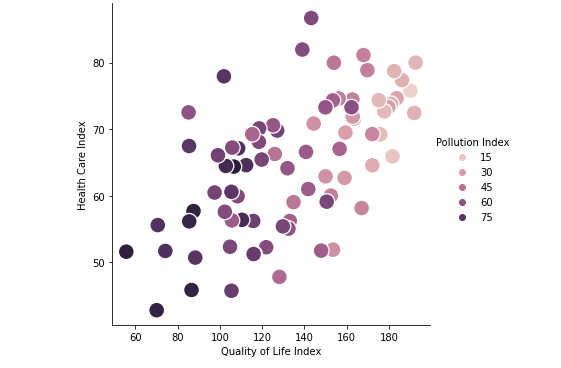
En este gráfico podemos ver que cuanto más limpio es el ambiente (más bajo está el índice de la contaminación), mejor es la calidad de vida y la salud de la población.
Histograma
Ahora vamos a crear un histograma usando la función de Seaborn sns.displot(). Los histogramas se aplican sobre todo para conocer la distribución de los datos. Sin embargo, esta representación está muy influenciada por el número de contendores (bins) que se elijan y el ancho de cada uno. Vamos a asignar 20 contenedores (bins=20) para representar como se distribuye el valor del equilibrio entre la vida y el trabajo de todos los encuestados:
sns.displot(df_wellbeing['WORK_LIFE_BALANCE_SCORE'],
bins=20)
Obtenemos el siguiente histograma:
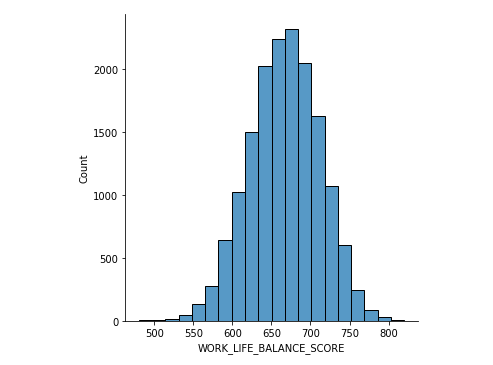
Podemos ver, que la gente suele tener el valor del equilibrio entre la vida y el trabajo enla zona entre 630 – 730, que según la información de la propia encuesta significa que tienen un equilibrio medianamente bueno, siendo el valor del equilibrio excelente a partir de 700.
Añadimos la meditación semanal para ver como se refleja el equilibrio entre la vida y el trabajo dependiendo de los días de meditación. Usamos sns.displot() y para añadir el dato de la meditación usaremos el parametro del gráfico hue (hue=»WEEKLY_MEDITATION»). Aparte, separamos el gráfico por género (col=»GENDER»):
sns.displot(df_wellbeing,
x="WORK_LIFE_BALANCE_SCORE",
hue="WEEKLY_MEDITATION",
col="GENDER" )
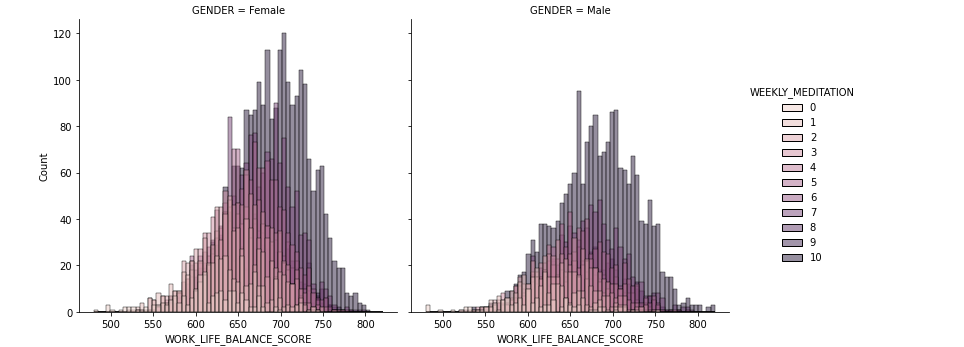
Vemos, que el gráfico refleja la tendencia general y la influencia de la meditación en el equilibrio entre la vida y el trabajo, donde la parte más oscura nos indica que la gente que dedica más tiempo a las meditaciones durante la semana suele tener mejor equilibrio entre la vida y el trabajo.
Gráfico KDE (KDE plot)
Otro gráfico que nos ayuda a ver la tendencia general es KDE plot (Kernel Density Estimation plot). Vamos a ver como se puede visualizar la distribución anterior usando este tipo de visualización de datos con la función sns.kdeplot():
sns.kdeplot(data=df_wellbeing['WORK_LIFE_BALANCE_SCORE'],
shade=True)
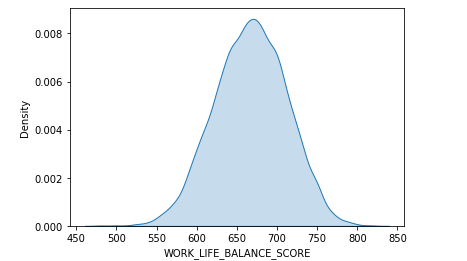
Vemos que este gráfico refleja la tendencia general y muestra el intervalo donde se obtiene la mayoría de los resultados (630 – 730).
Diagrama de caja (boxplot)
Ahora vamos a ver como se crean diagramas de caja (boxplots). Son útiles para conocer los rangos de datos, la media, el rango intercuartil en el que se distribuyen los datos, y ver si existen los valores atípicos (outliers). Seaborn tiene una función sns.boxplot() para crear este tipo de gráficos. En este caso para separar el gráfico por género, asignamos esta columna del dataset al eje X (x = «Gender») y el eje Y contendrá valores del equilibrio entre la vida y el trabajo:
sns.boxplot(data=df_wellbeing,
x="GENDER",
y="WORK_LIFE_BALANCE_SCORE")
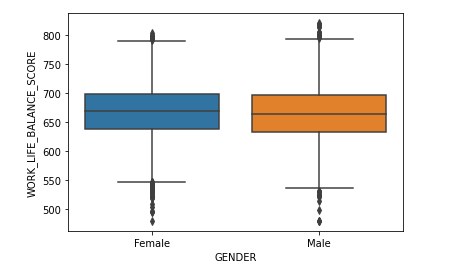
En este diagrama de caja se refleja perfectamente que la mayor parte de los encuestados tienen los valores del equilibrio entre la vida y el trabajo entre 630 y 700 tanto los hombres, como las mujeres.
Gráfico de violín (violin plot)
El último gráfico de la biblioteca Seaborn que veremos en este artículo es la conjunción del KDE plot y el diagrama de caja llamado el gráfico de violín. Este tipo de gráfico representa la distribución, su media, el rango intercuartil y el intervalo de confianza del 95% en el que se distribuyen los mapas. Se obtiene mediante la función sns.violinplot():
sns.violinplot(data=df_wellbeing,
x='GENDER',
y='WORK_LIFE_BALANCE_SCORE')
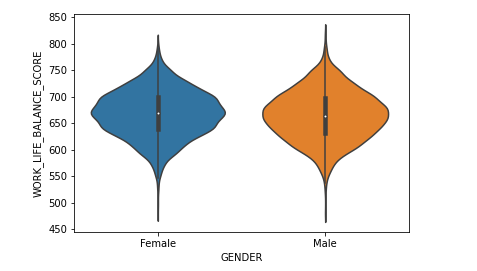
Aquí, el punto blanco es la media. La barra negra gruesa en el centro, representa el intervalo intercuartil y la barra fina negra que se extiende desde ella, representa el 95% de los intervalos de confianza.
Podemos aplicar el parámetro hue y ver la distribución no solo por género, sino también por edad (hue=»AGE»):
sns.violinplot(data=df_wellbeing,
x='GENDER',
y='WORK_LIFE_BALANCE_SCORE',
hue="AGE")
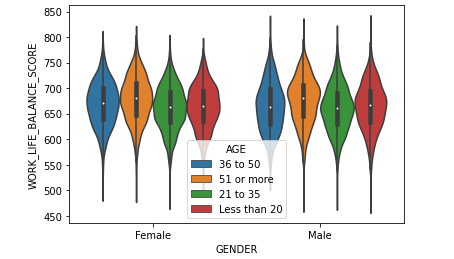
Con este gráfico podemos ver que la media cambia según la edad de los encuestados y que, para los que tienen más de 51 años el equilibrio entre la vida y el trabajo es en general más alto.
En este artículo hemos visto los aspectos generales de la visualización de datos en Python usando Pandas, Matplotlib y Seaborn. La elección del tipo de visualización depende de los datos que tenemos y los objetivos que queremos conseguir. Continuamente aumenta la cantidad de herramientas que ofrecen la creación de gráficos y la representación visual de la información en Python, pero incluso con las bibliotecas básicas se puede crear figuras limpias y descriptivas.