Trabajando con las tareas del PLN, casi siempre necesitamos preparar el texto antes del entrenamiento de los modelos de aprendizaje automático. Esta preparación (también llamada la normalización de texto o el preprocesamiento de texto), consiste en limpiar el texto de las cosas que no necesitamos. Si no lo hacemos, podemos obtener los resultados finales de nuestra tarea poco precisos e inconsistentes. Para ver los pasos más comunes del preprocesamiento de texto usaremos NLTK (Natural Language Toolkit). Veremos como trabajando con esta biblioteca y algunas funciones de Python adicionales podemos preparar el texto para las tareas del PLN como el Análisis de Sentimientos (Sentiment Analysis), la Extracción de Información (Information Extraction) y muchos más. El resultado final será un texto preprocesado, que podemos usar para nuestros objetivos del PLN.
¿En qué consiste la preparación de texto para poder trabajar con él e introducirlo a los modelos de aprendizaje automático? Podemos dividirlo en varias secciones. La primera parte en este caso constará en quitar los símbolos que no necesitamos. Eso puede incluir los siguientes pasos, dependiendo de nuestro objetivo final:
Cuando terminemos con esto, la otra parte del preprocesamiento de texto normalmente incluye:
La instalación de NLTK
Hemos elegido NLTK por varias razones. Es una de las herramientas más populares para trabajar con data del lenguaje natural, es libre y de código abierto, bastante simple de usar y tiene una comunidad grande y activa que soporta a la biblioteca y ayuda a mejorarla.
Para trabajar con la biblioteca NLTK primero tenemos que instalarla. Usaremos el pip installer, ya preinstalado en Python si usamos las versiones 2.7.9 y posteriores. Para las versiones anteriores de Python puede ser necesario instalar los setup tools e instalar pip, el sistema de gestión de paquetes de software, utilizando el comando:
sudo easy install pip
Seguiremos las instrucciones que nos indica la documentación de la biblioteca NLTK:
Si nuestro sistema es MAC/Unix/Linux:
1. Instalamos NLTK utilizando el comando: pip3 install nltk
2. Entramos en Python, tecleando en el terminal: python + Enter
introducimos: import nltk + Enter
Si ejecutamos el comando import nltk y no nos aparece ningún error, significa que todo se ha instalado bien.
Ahora tenemos que descargar los modulos de NLTK para poder usarlos luego. Ejecutamos el siguiente comando:
nltk.download()
Tiene que aparecer una nueva ventana con el Descargador de NLTK:
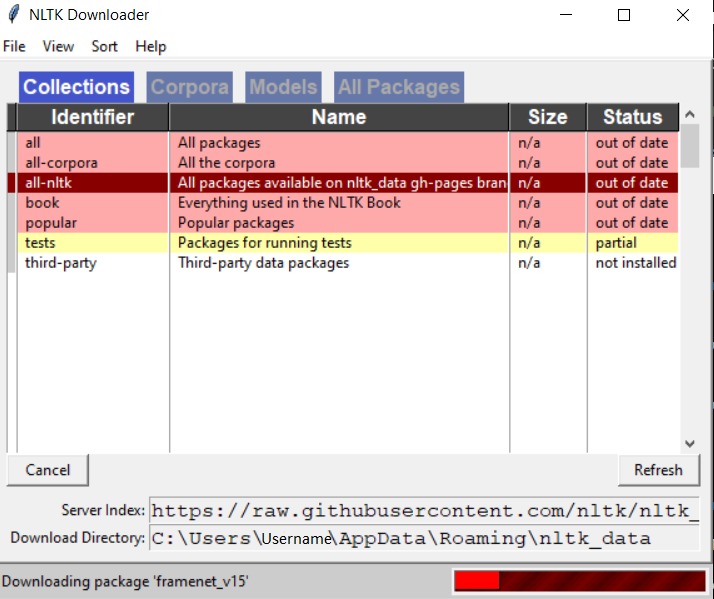
Para una installación central se aconseja cambiar la direccion de descarga a /usr/local/share/nltk_data para MAC y a /usr/share/nltk_data para Unix/Linux. Elegimos los paquetes, que queremos instalar (en nuestro caso instalamos all-nltk para tener todos los modulos de la biblioteca) y pulsamos «Download».
Si nuestro sistema es Windows:
En el caso de que aún no tengamos instalado Python en nuestro ordenador:
1) Instalamos Python 3.8, descargándolo aquí;
2) Instalamos NLTK. Para ello abrimos en el navegador de Windows el CMD (el análogo del Terminal en Unix/Linux) y entramos en el directorio, donde se ha instalado Python. Ejecutamos el siguiente comando:
pip3 install nltk
introducimos: import nltk + Enter
Si ejecutando el comando import nltk no nos aparece ningún error, significa que todo se ha instalado bien.
Ahora tenemos que descargar los modulos de NLTK para poder importarlos y usarlos luego. Ejecutamos el siguiente comando:
nltk.download()
Tiene que aparecer una nueva ventana con el Descargador de NLTK:
Para una installación central se aconseja cambiar la direccion de descarga a C:\nltk_data. Elegimos los paquetes, que queremos instalar (en nuestro caso instalamos all-nltk para tener todos los modulos de la biblioteca) y pulsamos «Download».
Ahora podemos empezar a usar la biblioteca y sus funciones para el preprocesamiento de texto.
La importación de las bibliotecas y los módulos
Empezamos a escribir nuestro código. Primero, tenemos que importar las bibliotecas y los módulos necesarios. Aparte de NLTK necesitaremos el módulo re, que permite trabajar con las expresiones regulares, el modulo string y unidecode. El resto de los módulos son los de NLTK (sus funciones las veremos más adelante).
El módulo string es un módulo básico de Python y tiene que estar instalado por defecto. El módulo unidecode es un módulo adicional, por eso lo tenemos que instalar a través del siguiente comando:
pip install unidecode
Ahora importamos la biblioteca NLTK y los modulos al comienzo de nuestro código:
import re
import nltk
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from nltk.stem.snowball import SnowballStemmer
import string
import unidecode
También tenemos que importar el fichero que contiene el texto con el que vamos a trabajar. En nuestro caso el fichero va a incluir el siguiente texto:
El procesamiento del lenguaje natural (PLN o NLP) es un campo que une 2 areas - la inteligencia artificial y la lingüística aplicada. Estudia las interacciones mediante el uso del lenguaje natural entre los seres humanos y las máquinas.
Importamos el fichero ‘texto.txt’, lo abrimos y lo leemos:
with open('texto.txt', 'r', encoding='utf-8') as f:
our_text = f.readlines()
Convertimos todas las letras en minúsculas
Empezamos el preprocesamiento de nuestro texto. Primero, vamos a convertir todas las letras en minúsculas. Esto se hace para reducir el volumen del vocabulario de nuestros datos textuales. Usaremos el comando text.lower(). Si aplicamos el comando al documento importado, nos va a salir un error:
'list' object has no attribute 'lower'
Esto pasa, porque el resultado del lector csv/txt es una lista y lower() funciona solo con los strings. Entonces, tenemos que convertir la lista en un string usando .join():
text_to_string = ''.join(our_text)
Ahora podemos aplicar el lower().Creamos una función, que nos va a convertir las letras en minúsculas:
def convertir_en_minusc(text):
text_min = text.lower()
return text_min
text_min = convertir_en_minusc(text_to_string)
Así es nuestro resultado:
Input:
El procesamiento del lenguaje natural (PLN o NLP) es un campo que une 2 areas - la inteligencia artificial y la lingüística aplicada. Estudia las interacciones mediante el uso del lenguaje natural entre los seres humanos y las máquinas.
Output:
el procesamiento del lenguaje natural (pln o nlp) es un campo que une 2 areas - la inteligencia artificial y la lingüística aplicada. estudia las interacciones mediante el uso del lenguaje natural entre los seres humanos y las máquinas.
Como podemos ver los comienzos de las frases igual que las letras de las abreviaciones se han convertido en minúsculas.
Eliminamos los dígitos
La eliminación de los dígitos nos puede ser útil en algunos casos del PLN, por ejemplo trabajando con el Análisis de los Sentimientos (Sentiment Analysis), donde los números no contienen ninguna información sobre los sentimientos.
Para eliminar los números, utilizaremos las expresiones regulares, concretamente re.sub(), sustituyendo los dígitos por los espacios en blanco:
def remove_numbers(text):
new_text = re.sub(r'\d+', '', text)
return new_text
Aplicamos la función a nuestro texto:
text_nonumb = remove_numbers(text_min)
El resultado es el siguiente:
Input:
el procesamiento del lenguaje natural (pln o nlp) es un campo que une 2 areas - la inteligencia artificial y la lingüística aplicada. estudia las interacciones mediante el uso del lenguaje natural entre los seres humanos y las máquinas.
Output:
el procesamiento del lenguaje natural (pln o nlp) es un campo que une areas - la inteligencia artificial y la lingüística aplicada. estudia las interacciones mediante el uso del lenguaje natural entre los seres humanos y las máquinas.
Como podemos ver, el número 2 que teniamos en nuestro texto ha desaparecido.
Para demostrarlo de una manera un poco más evidente, vamos a aplicar la función que hemos creado a un string que contiene varios dígitos: «3 gatos y 4 perros miraban por la ventana y veían 500 flores»
input_str = "3 gatos y 4 perros miraban por la ventana y veían 500 flores"
string_nonumb = remove_numbers(input_str)
El output que obtenemos es el siguiente:
gatos, perros miraban por la ventana y veían flores
Como podemos ver, todos los dígitos han desaparecido.
Eliminamos la puntuación y los símbolos innecesarios
Quitamos la puntuación para no tener más de una forma de la misma palabra. En el caso contrario el sistema va a tratar, por ejemplo, las palabras «¿Dónde?», «donde», y «donde.» como tres palabras distintas. Para eliminar la puntuación, utilizaremos el método maketrans(). Para usar este método, hemos importado la librería string (import string).
El método maketrans() nos devuelve una tabla de mapeo, que podemos usar con el método translate(). String.maketrans(x, y, z) tiene tres parámetros, donde el primer parámetro es un string que queremos reemplazar, el segundo – por qué lo reemplazamos, y el tercero – que parámetro queremos eliminar. El tercer parámetro en nuestro caso es string.punctuation, el cual contiene todos los conjuntos (sets) de puntuación.
Vamos a crear una función que elimina la puntuación y la aplicamos a nuestro texto:
def remove_punctuation(text):
translator = str.maketrans('', '', string.punctuation)
return text.translate(translator)
text_nopunct = remove_punctuation(text_nonumb)
Input:
el procesamiento del lenguaje natural (pln o nlp) es un campo que une areas - la inteligencia artificial y la lingüística aplicada. estudia las interacciones mediante el uso del lenguaje natural entre los seres humanos y las máquinas.
Output:
el procesamiento del lenguaje natural pln o nlp es un campo que une areas la inteligencia artificial y la lingüística aplicada estudia las interacciones mediante el uso del lenguaje natural entre los seres humanos y las máquinas
Vemos que ya no hay paréntesis, el guion en la primera frase y los puntos en los finales de las frases también han desaparecido.
Eliminamos los espacios en blanco
Después de quitar los dígitos y la puntuación, hay probabilidad de que nos queden unos huecos de espacios en blanco en el texto. Si nuestro corpus (el conjunto de textos) contiene los textos extraídos desde las redes sociales, muchas veces encontraremos el problema de los espacios en blanco excesivos. Para eliminar los espacios innecesarios, utilizamos los métodos .join() y split(). Combinando estos dos métodos, vamos a quitar todos los espacios en blanco (« ».join()) y luego separarlos por solo un espacio (split()).
Vamos a crear una función, que elimina los espacios en blanco excesivos:
def remove_spaces(text):
new_text = " ".join(text.split())
return new_text
Aplicamos la función a nuestro texto:
text_nospace = remove_spaces(text_nopunct)
Obtenemos el resultado:
Input:
el procesamiento del lenguaje natural (pln o nlp) es un campo que une areas la inteligencia artificial y la lingüística aplicada. estudia las interacciones mediante el uso del lenguaje natural entre los seres humanos y las máquinas.
Output:
el procesamiento del lenguaje natural pln o nlp es un campo que une areas la inteligencia artificial y la lingüística aplicada estudia las interacciones mediante el uso del lenguaje natural entre los seres humanos y las máquinas
Convertimos los acentos ortográficos y otros signos diacríticos en un formato común
Las lenguas como el castellano y el francés incluyen muchas palabras que llevan tilde y contienen otros signos diacríticos. Podemos convertirlos y estandarizarlos, ya que si no nuestro modelo de PLN tratará las palabras como «café» y «cafe» como dos cosas diferentes, aunque tengan el mismo significado (volvemos al ejemplo con las redes sociales, donde los usuarios muchas veces no respetan las normas de ortografía). Para conseguirlo, usaremos el módulo unidecode(). Este módulo acepta los datos en el formato Unicode e intenta representarlos en los carácteres ASCII.
Vamos a crear una función, que procesará el texto que contiene las palabras con signos diacríticos y nos devolverá el texto sin estos signos:
def remove_diacritics(text):
new_text = unidecode.unidecode(text)
return new_text
Aplicamos la función a nuestro texto:
text_noaccent = remove_diacritics(text_nospace)
Vamos a ver el resultado:
Input:
el procesamiento del lenguaje natural pln o nlp es un campo que une areas la inteligencia artificial y la lingüística aplicada estudia las interacciones mediante el uso del lenguaje natural entre los seres humanos y las máquinas
Output:
el procesamiento del lenguaje natural pln o nlp es un campo que une areas la inteligencia artificial y la linguistica aplicada estudia las interacciones mediante el uso del lenguaje natural entre los seres humanos y las maquinas
Como podemos ver, las letras en las palabras lingüística y máquinas han perdido sus signos diacríticos y se han convertido en linguistica y maquinas.
Tokenización
La tokenización es un proceso que divide textos y frases en unas piezas más pequeñas, los tokens. Estas piezas pueden ser palabras sueltas o frases, dependiendo de lo que necesitamos. Para tokenizar el texto por palabras usaremos el módulo word_tokenize(), que hemos importado de la biblioteca NLTK (from nltk.tokenize import word_tokenize, sent_tokenize), igual que sent_tokenize(), que usaremos para tokenizar el texto por frases.
La tokenización es un paso previo a los procesos como la eliminación de las palabras vacias (las stopwords), el stemming o la lematización, así que se usa bastante a menudo.
Creamos una función para obtener los tokens y la aplicamos a nuestro texto:
def tokenize_words(text):
text_tokenized = word_tokenize(text)
return text_tokenized
text_token = tokenize_words(text_noaccent)
Input:
el procesamiento del lenguaje natural pln o nlp es un campo que une areas la inteligencia artificial y la linguistica aplicada estudia las interacciones mediante el uso del lenguaje natural entre los seres humanos y las maquinas
Output:
['el', 'procesamiento', 'del', 'lenguaje', 'natural', 'pln', 'o', 'nlp', 'es', 'un', 'campo', 'que', 'une', 'areas', 'la', 'inteligencia', 'artificial', 'y', 'la', 'linguistica', 'aplicada', 'estudia', 'las', 'interacciones', 'mediante', 'el', 'uso', 'del', 'lenguaje', 'natural', 'entre', 'los', 'seres', 'humanos', 'y', 'las', 'maquinas']
Veremos también la tokenización por frases. Para esto tenemos que saltar el paso de la eliminación de la puntuación, para que el sistema entienda la división entre las frases. Vamos a verlo con un texto sencillo:
input_str = "Hola, como estas. Estoy bien, gracias. Quedamos manana. Un saludo."
Creamos una función que va a tokenizar el texto por frases y la aplicamos a nuestro texto:
def tokenize_sentences(text):
text_tokenized = sent_tokenize(text)
return text_tokenized
sent_text = tokenize_sentences(input_str)
Así es el resultado:
Input:
¿Hola, como estás? Estoy bien, gracias. Quedamos mañana. Un saludo.
Output:
['Hola, como estas.', 'Estoy bien, gracias.', 'Quedamos mañana.', 'Un saludo.']
Como podemos ver, el texto del ejemplo se ha dividido por frases, los que ahora son los tokens.
Quitamos las palabras vacías (las stopwords)
Las palabras vacías (las stopwords) son las palabras que no contienen la información necesaria para el análisis de nuestro texto y/o no contribuyen de ninguna manera al sentido de la frase. Así que los podemos eliminar sin perder el contenido esencial. Normalmente estas palabras son los artículos, verbos auxiliares, las preposiciones, etc. La biblioteca NLTK contiene las stopwords para varios idiomas, este módulo lo hemos importado al principio de nuestra pequeña guía (from nltk.corpus import stopwords).
Vamos a crear una función, que elimina las palabras vacías en castellano. La función va a buscar si la palabra que está en nuestro texto también está en la lista de las palabras vacías, y si es así, no la incluye en la nueva lista ‘text_without_stopwords’.
def delete_stopwords(text):
stop_words = set(stopwords.words("spanish"))
text_without_stopwords = [word for word in text if word not in stop_words]
return text_without_stopwords
Aplicamos la función a nuestro texto y miramos el resultado:
filtered_text = delete_stopwords(text_token)
Input:
['el', 'procesamiento', 'del', 'lenguaje', 'natural', 'pln', 'o', 'nlp', 'es', 'un', 'campo', 'que', 'une', 'areas', 'la', 'inteligencia', 'artificial', 'y', 'la', 'linguistica', 'aplicada', 'estudia', 'las', 'interacciones', 'mediante', 'el', 'uso', 'del', 'lenguaje', 'natural', 'entre', 'los', 'seres', 'humanos', 'y', 'las', 'maquinas']
Output:
['procesamiento', 'lenguaje', 'natural', 'pln', 'nlp', 'campo', 'une', 'areas', 'inteligencia', 'artificial', 'linguistica', 'aplicada', 'estudia', 'interacciones', 'mediante', 'uso', 'lenguaje', 'natural', 'seres', 'humanos', 'maquinas']
Como podemos ver, han desaparecido las palabras como ‘el’, ‘del’, ‘o’, ‘un’, ‘que’, ‘la’, ‘y’, ‘las’, ‘los’ y solo han quedado las palabras que contienen la información necesaria del texto.
Radicalización (stemming)
La radicalización (stemming) es un proceso de la reducción de la inflexión de una palabra a su raíz, quitando los afijos: prefijos, sufijos e infijos. El resultado que obtenemos no siempre es una palabra que existe, sino su base o stem. El stemming ayuda a reducir el volumen del vocabulario (el número de las palabras usadas en el corpus) para las tareas como, por ejemplo, la similitud de los documentos. El proceso ayuda a nuestro sistema de aprendizaje automático a funcionar más rápido y más eficiente.
Stemming es una de las herramientas que se puede aplicar a través de la biblioteca NLTK. Esta biblioteca tiene varios stemmers, pero para trabajar con las lenguas distintas al inglés unos serán más eficientes que otros. Nosotros usaremos el Snowball Stemmer que soporta 14 idiomas y el castellano es uno de ellos.
Importamos el Snowball Stemmer (from nltk.stem.snowball import SnowballStemmer) y creamos una función, que nos devolverá los stems de las palabras del texto. Tenemos que indicar en que idioma trabajamos, para que el stemmer funcione correctamente:
def stemming(text):
stemmer = SnowballStemmer("spanish")
text_stemmed = [stemmer.stem(word) for word in text]
return text_stemmed
Aplicamos la función a nuestro texto:
text_stem = stemming(filtered_text)
Así es el resultado:
Input:
['procesamiento', 'lenguaje', 'natural', 'pln', 'nlp', 'campo', 'une', 'areas', 'inteligencia', 'artificial', 'linguistica', 'aplicada', 'estudia', 'interacciones', 'mediante', 'uso', 'lenguaje', 'natural', 'seres', 'humanos', 'maquinas']
Output:
['proces', 'lenguaj', 'natural', 'pln', 'nlp', 'camp', 'une', 'are', 'inteligent', 'artificial', 'linguist', 'aplic', 'estudi', 'interaccion', 'mediant', 'uso', 'lenguaj', 'natural', 'ser', 'human', 'maquin']
Para ver como funciona el stemming con las palabras con la misma raíz, vamos a aplicar nuestra función a un string: «Lengua, lenguas, lenguaje, lenguajes»:
input_str = "Lengua, lenguas, lenguaje, lenguajes"
Tenemos que tokenizar el string antes de poder aplicar el stemming, para eso usamos la función de tokenización que hemos creado en el paso anterior :
str1 = tokenize_words(input_str)
Aplicamos la función de stemming:
str1_stemmed = stemming(str1)
El resultado que obtenemos:
['lengu', ',', 'lengu', ',', 'lenguaj', ',', 'lenguaj']
Como podemos ver, en las dos primeras palabras se les ha quitado los sufijos –a y –as y han quedado con la base (stem) ‘lengu’, las últimas dos palabras – con la base (stem) ‘lenguaj’.
Así, dependiendo de nuestras necesidades, a la hora de trabajar con el texto podemos necesitar todas o solo una parte de las funciones, presentadas en este artículo. El preprocesamiento de texto nos ayuda a trabajar solo con la información que realmente necesitamos para el aprendizaje automático, limpiando el ruido de las palabras y símbolos innecesarios.