¿Qué es el GPT-3?
El GPT-3 (Generative Pre-trained Transformer 3) es el modelo del lenguaje, que emplea aprendizaje profundo para producir textos parecidos a la redacción humana. Fue creado por OpenAI, una investigadora californiana co-dirigida por Elon Musk y Sam Altman. Es ya la tercera generación de este tipo de transformadores y el avance tecnológico más importante en los últimos años. Hoy en día es el modelo del lenguaje más complejo y más voluminoso de todos los que existen.
Basado en la arquitectura «transformador» igual que sus predecesores el GPT-1 y el GPT-2 , el GPT-3 es capaz de responder a cualquier texto introducido por el usuario con un trozo de texto nuevo generado de acuerdo con el contenido proporcionado. Es un avance muy potente, ya que los modelos del lenguaje anteriores no tenían la capacidad de generar texto parecido al escrito por un humano.
Lo que destaca al máximo el GPT-3 es su habilidad de ser aplicado a cualquier tarea de PLN sin ajustarlo para una tarea en concreto. Lo único que hace falta, es introducirle un par de ejemplos para que realize lo que queremos (el concepto conocido como few-shot learning). Ningún modelo del lenguaje anterior puede hacer esto – la mayoría de los modelos necesitan un proceso de ajuste que incluye la recolección de ejemplos para el aprendizaje. Es un logro muy importante que hace al GPT-3 un modelo del lenguaje prometedor en el mundo del PLN.
Presentado al público en mayo 2020 este algoritmo es capaz de escribir textos largos, poesía, noticias, responder preguntas, hacer traducciones, escribir música, programar, resolver tareas matemáticas y todo esto sin depender del contexto. Lo que hace falta es describirle lo que queremos en lenguaje natural y esperar al resultado.
¿Cómo ha sido entrenado el GPT-3?
El GPT-3 es un modelo del lenguaje basado en una red neuronal. Este tipo de modelos predicen la posible existencia de las frases calculando la probabilidad condicional de las palabras – la frecuencia con la que aparece la palabra basandose en otras palabras del texto. Por ejemplo, un modelo del lenguaje va a etiquetar la frase «Estoy hablando con un amigo» como mucho más probable en comparación con la frase «Estoy hablando con una manzana», descartando así la última de las frases ya que no tiene tanto sentido.
El GPT-3 fue entrenado con un dataset de textos no etiquetado con un volumen nominal de 45TB, que luego fue preprocesado para eliminar los duplicados, resultando en un tamaño final alrededor de 600GB. Es el dataset más grande usado por el momento para el entrenamiento de los modelos del lenguaje. La mayor fuente de los datos textuales (60% de todo el dataset) ha sido el CommonCrawl, que contiene páginas web entre 2016 y 2019. En adición, se ha usado toda la Wikipedia escrita en inglés, libros, poemas, las noticias de diferentes periódicos publicados en Internet, códigos de GitHub, guías de viaje e incluso recetas de cocina. Aproximadamente el 7% del material está en idiomas extranjeros, lo que permite al modelo no solo generar textos de cualquier ámbito, sino también traducirlos. La flexibilidad con los diferentes idiomas es una de las claves del nuevo transformador creado por OpenAI, aunque el inglés sigue siendo su idioma principal.
El GPT-3 tiene 8 tamaños, empezando desde 125 millones hasta 175 mil millones de parámetros, lo que lo hace el modelo del lenguaje más potente del momento. Los parámetros en este caso son unas variables que la red neuronal optimiza durante su entrenamiento. Si lo comparamos con los modelos existentes, el predecesor del modelo actual el GPT-2 tiene solo 1,5 mil millones de parámetros, y el segundo modelo del lenguaje más potente Microsoft Turing-NLG tiene 17 mil millones. La comparación de la cantidad de parámetros entre los modelos anteriores y el actual la podemos ver en la siguiente imagen:
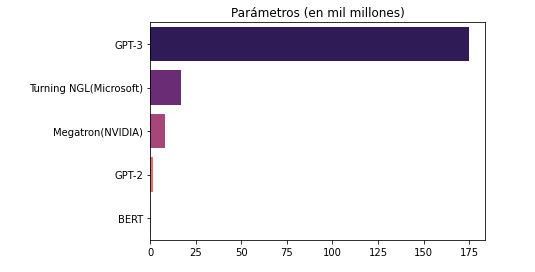 Fuente: Search Engine Watch
Fuente: Search Engine Watch
En el desarrolo de una red neuronal de este tipo el mayor objetivo que tiene el modelo es encontrar patrones en los datos usando las regularidades estadísticas. En la fase de entrenamiento el GPT-3 recibe milliones ejemplos de textos, convirtiendo las palabras en vectores (sus representaciones numéricas). Después intenta convertir estos vectores en palabras otra vez y crear frases que tengan sentido, usando la probabilidad condicional de las palabras. Repite este proceso una y otra vez hasta que consigue la mayor precisión posible.
Lo más importante es que este proceso no está bajo control humano – el programa busca los patrones solo. Cuando el modelo ya está entrenado, pasamos a la fase de inferencia de aprendizaje automático donde el modelo practica sus conocimientos. Tenemos que introducir una o varias palabras al programa para que prediga lo que tiene que ir a continuación. Por ejemplo, si introducimos la palabra «café» al GPT-3 el modelo sabe, basándose en los pesos de su red, que las palabras «taza» y «beber» son mucho más probables que las palabras «champú» o «entrevista».
¿Qué puede hacer el GPT-3?
La lista de tareas que se puede hacer usando el GPT-3 es muy larga. Ahora mismo funciona a través de la API de OpenAI que ya se ha utilizado en la creación de muchas aplicaciones. Una de las funciones más destacadas es la posibilidad de crear textos parecidos a la redacción humana. Se aplica en la creación de servicios para escribir el correo electrónico, anuncios y artículos de blogs. También se puede aplicar en los juegos como AI Dungeon, donde todas las respuestas están determinadas por el modelo del lenguaje. Si antes el desarollador del juego tenía que crear un arbol de decisiones y las opciones textuales a elegir, ahora es posible tener cualquier continuación de la historia que no sea predeterminada. El feedback de los usuarios sobre AI Dungeon es muy positivo, destacan la rapidez, la calidad de las conversaciones, y las suscripciones al juego han aumentado un 25%. La capacidad de generar texto adecuado por el modelo se ha introducido también en el blog de ciencia AI Weirdness donde su autora Janelle Shane generó las ideas creativas para sus artículos del blog y tweets usando la API de OpenAI.
Otra área muy potente son los chatbots. Basandose en la API de Open AI se ha creado Replika, una IA personal que ofrece un espacio donde puedes hablar sobre tus pensamientos, sentimientos, creencias, experiencias y memorias. Resulta ser una especie de compañero-IA. La red social AI Channels donde puedes conversar con los «agentes de IA» está usando la misma API. Por ejemplo, puedes pedir a un agente recomendarte alguna película o participar en una discusión con intelectuales famosos como Albert Einstein. A diferencia de los chatbots que conocemos, que tienen una base de respuestas definidas, AI Channels genera respuestas nuevas y puede responder a preguntas imprevistas.
La API de OpenAI se usa también para la búsqueda semántica. Permite hacer una búsqueda en documentos basada en el lenguaje natural y no por palabras clave. Esta función es la base de Casetext, la plataforma que ayuda a los abogados a encontrar precedentes y escribir informes. Resulta ser una herramienta de gran ayuda porque la búsqueda de artículos legales puede llevar mucho tiempo y de esta manera se hace mucho más rápido y efectivo. Otra plataforma que ha usado el modelo del lenguaje de OpenAI para mejorar sus resultados es Algolia. Ofrece al usuario una búsqueda relevante y rápida usando la web, aplicación móvil o aplicación de voz. Integrando la API de OpenAI, Algolia puede responder a las preguntas hechas en lenguaje natural 4 veces más rápido que usando BERT.
Otra función del GPT-3 que ha llamado mucho la atención es la capacidad del modelo de solucionar las tareas de programación. Podemos pedir al programa que nos genere un código de Python explicando la tarea en lenguaje natural y lo hace bastante bién. De esta manera, usando el GPT-3 se puede simplificar la recopilación de estadísticas sobre los usuarios de un sitio web o usar las partes de código que ofrece el programa para crear modelos de aprendizaje automático.
Estas son solo algunas de las miles de maneras de utilizar el GPT-3. Hemos visto que lo podemos usar para las aplicaciones web basadas en lenguaje natural y para tareas de traducción ya que ha aprendido de las páginas web en otros idiomas, aunque el inglés lo domina mucho mejor. Al ser tan flexible y universal, podemos usar este modelo del lenguaje en escenarios aún más complejos como los servicios de atención al cliente, plataformas educativas y mucho más.
¿Es el GPT-3 tan perfecto como parece?
Como hemos podido ver, el GPT-3 demuestra que un modelo del lenguaje puede resolver tareas de PLN que nunca ha visto antes. Ahora mismo el programa está en la versión beta y se puede acceder a través de la API proporcionada por OpenAI. Para poder utilizar esta API hace falta apuntarse a la lista de espera y tener paciencia, ya que muchos usuarios tienen ganas de probarlo. La razón de no dar acceso libre al GPT-3 es para poder controlar el uso del programa, y sobre todo para prevenir el uso maléfico. Aparte, la versión beta está limitada a cierto número de pruebas y si queremos disfrutar más de un invento tan poderoso, tendremos que suscribirnos.
Aunque este modelo del lenguaje es muy prometedor, tiene sus inconvenientes. Primero, requiere mucha memoria, por lo que se queda fuera de uso en muchas empresas. Segundo, los textos que genera parecen muy impresionantes a primera vista, pero si hablamos de textos largos, muchas veces el modelo no es capaz de mantener todas las partes de texto interconectadas entre sí y a veces se pierde el sentido general.
Entrenado con la información recolectada de Internet, el modelo puede generar textos con notas de racismo o sexismo porque no sabe distinguir lo que es apropiado. Aparte, no distingue las noticias verdaderas de las falsas, lo que puede complicar su uso en ciertos tipos de tareas. También hay razones para dudar que el GPT-3 entiende los significados de las palabras que usa, dado que ha aprendido solo desde las descripciones textuales de procesos y eventos y no ha podido aplicar su conocimiento a los conceptos reales de una manera como lo hacemos los humanos. En cuanto al idioma, solo el 7% de los textos que ha usado para su entrenamiento son en idiomas extranjeros, lo que por ahora limita su uso a los que saben inglés. El GPT-3 es sin duda un gran avance tecnológico, pero todavía queda mucho para que este tipo de modelos funcione parecido a la mente humana.
«El bombo que se le está dando al GPT-3 es demasiado. Es impresionante (¡gracias por los cumplidos!) pero todavía tiene graves debilidades y a veces hace unos errores muy tontos. La IA va a cambiar el mundo, pero el GPT-3 son solo los primeros pasos. Nos queda mucho por averiguar.»
Sam Altman, CEO de OpenAI (traducción de su tweet original)